3D-Grafikprojekt
Karsten Becker und Tim Böscke
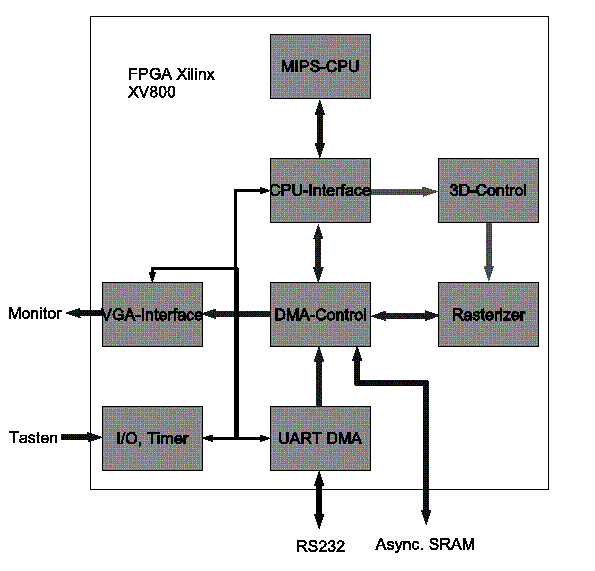
Unser Ziel ist es für dieses System on a Chip (SOC) Seminar einen
3D-Core für einen Xilinx-FPGA zu schreiben. Dieser sollte aus
einem in C programmierbaren Prozessor und
einer 3D-Einheit bestehen.
Der Prozessor hat dabei die Aufgabe die Dreiecksdaten zu berechnen
und sie
an die 3D-Einheit weiterzugeben. Diese sorgt dann dafür, dass die
Dreiecke
gezeichnet und texturiert werden.
Zur Realisierung des Prozessorkerns wurde der OpenIP-core Plasma von
openCores.org benutzt. Zur Realisierung steht uns das XSV Board von
Xess zur
Verfügung.
Es gab viele Überlegungen wie die Gesamtarchitektur aussehen
sollte. Das grösste
Problem bei der Realisierung waren die konkurrierenden
Speicherzugriffe. Jede Einheit benötigt Speicher. Die erste
Überlegung war für alle Einheiten einen eigenen
Speicher auf dem Board vorzusehen. Das brachte jedoch Probleme mit der
Anzahl der verfügbaren Pins und der Frage wie denn Daten zwischen
zwei Modulen hätten ausgetauscht
werden sollen. Deshalb, und weil man einfacher auf andere Speichertypen
adaptieren kann,
haben wir uns für einen zentralen DMA-Controller entschieden, an
dem alle Module als
Master dranhängen.
Alle Module verfügen über eine direkte oder indirekte
Anbindung über den DMA-Controller
an den Speicher.
Bei dem CPU-Modul handelt es sich um einen Mips-Prozessor, der von
Opencores.org stammt
und dort Plasma heißt. Er versteht die meisten Mips-1 Befehle.
Das CPU-Interface beinhaltet den Daten- und Befehlscache und stellt
außerdem den Zugriff auf die anderen Module per Memory-mapping
bereit. Außerdem enthält es noch das Bootstrap.
3D-Control bekommt seine Konfigurationsdaten über den 3D-Bus.
Seine Aufgabe ist es die Trapezoide Zeilenweise zu zerlegen und die
gewonnen Parameter an den Rasterizer zu übergeben.
Der Rasterizer füllt die ihm übergebenen Parameter mit einer
Textur und Schattierung.
Das VGA-Modul bekommt die Startadresse des Framebuffers als Parameter
und sorgt für eine dem Monitor angenehme Umsetzung des Pixels.
Außerdem sind hier die verschiedenen Dithering Methoden und der
XOR-Filler integriert.
Das DMA-Modul ist die zentrale Stelle zum Speicher. Jedes Modul, mit
Ausnahme von 3D-Control, ist über mindestens einen Bus daran
gekoppelt. Hier ist das RAM direkt angebunden.
Das UART Modul dient der Übertragung von Daten in beliebige
Bereiche des Speichers.
Bei der CPU handelt es sich um den Plasma Core, der auf
www.opencores.org verfügbar ist. Er versteht die meisten Mips-1
Befehle. Außerdem wird eine Toolchain mitgeliefert, mit der man
einfache Programme compilieren kann. Ich erspare mir hier die
detailierte Dokumentation der MIPS-1 Architektur, da sie zum einen auf
der Homepage von MIPS frei verfügbar ist und außerdem auch
von einem Partnerprojekt nochmals detailierter beschrieben wird.
Bei dem Prozessor handelte es sich leider um einen nicht besonders gut
getesteten Core. Zwei Bugs waren besonders schwerwiegend.
Der Operand Bypass wird benötigt, wenn das Resultat einer
ALU-Operation
direkt im nächsten Befehl wieder verwendet wird. Da das
Schreiben/Lesen
aus dem Registerfile durch das Pipelining um einen Taktzyklus versetzt
erfolgt, wird für diesen Fall eine Sonderbehandlung benötigt.
Diese hat
im Zusammenhang mit dem von uns benutzen "`Pause"' nicht richtig
funktioniert.
Sehr interessante Fehler besorgte uns die etwas merkwürdige
Toolchain. Anstatt komplett die GNU-Toolchain zu verwenden, setzte der
Programmierer auf ein selbstgeschriebenes Tool, das an einer festen
Stelle im Elf-File den Operator und Argument ersetzte. Leider schienen
auf dem Prozessor aber noch nie größere Programme gelaufen
zu sein, denn die ersten 16-Bit des Stack-Pointers (SP) wurden nicht
initialisiert. Das führte dazu, dass der SP mitten in wichtigen
Programmteilen saß und so zu unkontrollierbaren Abstürzen
führte.
Der Prozessor selber muß sicherlich erst einmal in das VHDL
Design eingebaut werden. Die Schnittstellen sind relativ gut
erklärt. Es empfiehlt sich jedoch das Registerfile von den
Generics zu befreien und durch eine dem FPGA entsprechende
Implementation zu ersetzen.
Außerdem hat sich die Verwendung des DMAs als sehr nützlich
erwiesen, so dass man erwägen sollte, sie auch bei eigenen Designs
weiter zu verwenden. Das CPU-Interface sorgt außerdem dafür,
dass man den Prozessor komplett Asynchron zum System-Bus takten kann,
was bei der nicht gerade überragenden Geschwindigkeit des
Prozessors von Vorteil ist.
Um den oben genannten Bug mit der alten Toolchain zu umgehen, wurde
eine Neue entwickelt, die komplett auf den etablierten GNU-Tools
aufsetzt. Die Benutzung der neuen Toolchain wird ausführlich in
QuickOverview.html beschrieben.
Um die Toolchain nutzen zu können, muss man sich einen
Crosscompiler für das mips-elf-target bauen. Zum Compilieren
benötigt man 3 Dateien die unter Umständen etwas angepasst
werden müssen.
Um dem Problem der fehlerhaften Toolchain zu umgehen, wurde ein
Linkerscript geschrieben, das alle zur Initialisierung nötigen
Symbole setzt. Dazu wurden am Anfang erst einmal die Speicherbereiche
definiert. In unserem Fall begann das Programm memory bei der Adresse
0x800 und war 0x3F800 lang.
Die nachfolgenden Symboldefinitionen sind mit Sicherheit nicht der
eleganteste Weg, funktionieren aber wie sie sollen. Man wird sie
später mit nm wiederfinden. Der Sinn dieser Symbole liegt darin,
Zahlenwerte bereitzustellen, auf die man im boot.asm später wieder
zugreifen kann. Der Linker ersetzt nämlich die im .asm vorhandenen
Symbole durch den entsprechenden Zahlenwert.
Das Makefile ist größtenteil generisch. Man benötigt
nur die zu kompilierenden c Dateien unter SOURCES.c anzuhängen und
evtl. vorhandene Assemblerstücke bei SOURCES.asm. Hierbei muss
dringend beachtet werden, dass boot.asm immer das erste Assemblerfile
ist, weil hier wichtige Variablen und Speicherbereich initialisiert
werden.
Die Toolchain für das Bootstrap sieht etwas anders aus. Um das
Bootstrap nicht immer neu einzukompilieren wird ein Tool genommen, das
den Speicherinhalt des Bootstraps direkt in den Configurationsbitstream
einfügt. Allerdings wird hier noch das etwas abenteuerliche
convert.exe benutzt, da die Datei bootstrap_be.txt benötigt wird,
die von diesem Programm erzeugt wird.
Zuerst wird das Programm mit dem Befehl Makefile kompiliert und
anschließend wir das Bootstrap mit dem Befehl Makebit in den
Bitstream eingefügt. Dazu werden die Dateien block_bd.bmm und
System.bit benötigt, die als Compilat vom ISE abfallen. Diese
müssen also nach jedem Erzeugen des Programmingfiles neu in das
Verzeichnis, indem Makebit liegt, kopiert werden.
Da wir mit der CPU nicht auf einen angemessenen Takt hoch kamen,
mussten wir uns Möglichkeiten überlegen wie wir die Effizienz
der CPU anheben konnten. Dazu konstruierten wir ein CPU-Interface, das
die CPU komplett über Caches und FIFOs von der restlichen
Clockdomain abgrenzt. Die CPU kann also komplett Asynchron getaktet
werden. Außerdem bot sich dadurch eine gute Stelle, in der wir
die verschiedenen Busse memory mapped anbringen konnten.
Damit die CPU weiterarbeiten konnte, während das 3D-Modul die
Daten gezeichnet hatte, gab es einen FIFO der von der CPU beschrieben
und von dem 3D-Modul gelesen wurde. Der von uns eingesetzte Cache
erreichte einen Wirkungsgrad von über 80%,was den DMA doch
spürbar entlastete und so mehr Speicherzugriffe für den Rest
der Hardware bereitstanden.
Desweiteren enthält das CPU-Interface auch noch das Bootstrap,
das immer als erstes ausgeführt wird, bevor es dann auf
User-Interaktion in den echten Speicher springt.
Das 3D-Modul teilt sich in zwei Teile auf: Dem 3D-Control und dem
Rasterizer.
3D-Control zerlegt die vom CPU-Treiber übergebenen Trapezoide
weiter in einzelne
Zeilen. Da diese Aufgabe relativ Zeitkritisch ist, wird sie von einer
dedizierten Hardware übernommen, die parallel zur Haupt-CPU
arbeiten kann.
Die Positions- und Texturdaten der Zeilen werden über einen
eigenen Bus
direkt an den Rasterizer übergeben. Auch die sogenannte
"`Subtexelkorrektur"'
erfolgt in dieser Einheit.
Die 3D-Control Einheit wurde durch einen kleinen RISC-Prozessor in
Harvard-
Architektur implementiert. Diese CPU verfügt über 16 Register
und ist
in der Lage, Additionen, Multiplikationen, Sprünge und I/O Befehle
auszu-
führen. Die Programmdaten sind in einem kleinen ROM mit max. 32
Einträgen
abgelegt.
Pro Trapezoidzeile müssen ca. 7 Additionen, 2 Multiplikationen
und diverse
weitere Befehle ausgeführt werden.
Der Rasterizer bekommt Positions- und Steigungsdaten von der 3D-Control
Einheit.Er interpoliert die Texturkoordinaten, liest die Texturdaten
aus dem
Speicher und schreibt die einzelnen Pixel an die angegebenen Positionen
des
Bildschirmspeichers.
Nach dem Zeichnen einer Zeile geht der Rasterizer in den
Idle-Zustand und
erwartet neue Daten.
Dieses Modul sorgt dafür, dass die Daten, die im Framebuffer
gespeichert sind, auf dem Monitor dargestellt werden. Dazu liest es die
Daten in einen Buffer während der Blankzeit. Aus diesem Buffer
erzeugt das Modul dann das korrekte timing für den Monitor. Dabei
werden die 16-Bit Farbwerte in die 8-Bit Werte umgewandelt, die
später auf dem Monitor zu sehen sind. Damit es nicht allzu
kümmerlich aussieht, wird ein Dithering der Farben vorgenommen.
Dazu sind zwei Verfahren implementiert, die sich über
Steuerleitungen ein und ausschalten lassen.
Außerdem enthält das VGA-Modul auch den XOR-Filler, der
für die einfachste Art der Texturierung vorgesehen ist. Bei dem
Xorfiller werden die Pixel mit dem vorherigen Pixel gexored und auf
diese Weise ganze Flächen zwischen Linien mit einer Farbe
gefüllt. Der Nachteil dieses Verfahrens ist eindeutig. Linien, die
sich eigentlich auf der Objekt-Hinterseite befinden, werden auch
verxored und so entstehen Farbwechsel in Bereichen, in denen keine sein
sollten. Zudem lassen sich nur einfarbige Flächen darstellen.
Um einen DMA-Controller implementieren zu können, muss man sich
zunächst
um die Strukturierung des Speichers Gedanken machen. Auf dem
demnächst
verfügbaren Prototypenboard wäre ein DDR-Speicher
ansprechbar. Leider
wissen wir aber zu wenig über die dazu nötigen IP-Cores.
Außerdem
hat der DDR-Speicher zwar einen enorm hohen Datendurchsatz, den er
aber nur bei großen Datenmengen erreichen kann. Bei kleineren
Datenmengen
ist die Latenz zu hoch um einen einigermaßen sinnvollen Durchsatz
zu erreichen. Hinzukommt auch, dass der DDR-Speicher ganz anders
angesprochen
wird als der SRAM-Speicher, der auf dem "`alten"' Prototypenboard
verfügbar ist.
Die sinnvollste Variante ist also ein SRAM zu benutzen, da die
Programmierung
ausgesprochen einfach ist und es sich gut mit kleinen Datenmengen
versteht. Außerdem ist schon SRAM auf dem Board vorhanden. Die
Speicheraufteilung ist 2*(16*512).
Um herauszufinden ob wir über eine Priorisierungstabelle oder
einen Zeitmultiplex
den Zugriff aufs Ram verteilen, haben wir probiert den
Bandbreitenbedarf der einzelnen
Module zu schätzen.
Bei dem CPU-Modul können wir mit einem Takt von vorraussichtlich
33MHz rechnen. In jedem
Takt werden Daten gelesen und geschrieben. Wir würden hier also
132MByte/sek (32-Bit Zugriff)brauchen. Allerdings
können wir die CPU zu jedem beliebigen Zeitpunkt anhalten, so das
wir keinen konstanten Datenstrom
brauchen.
Das Textur-Modul benötigt eigentlich einen konstanten Datenstrom.
Man kann hier jedoch hervorragend
Cachen. Die zu erwartende Datenrate wir gleich dem Takt sein. Das Modul
hängt von den Daten des Pixel-Moduls ab. Wenn das Pixel-Modul
keine Daten mehr liefert, benötigt auch das Textur-Modul keine
Daten mehr.
Das Pixel-Modul braucht auch einen konstanten Datenstrom; Allerdings
nur solange wie es Daten von
der CPU zu bearbeiten hat.
Dieses Modul ist das Kritischste, denn es benötigt eine hohe
Bandbreite von 1024*393*61=23,41MByte/sek.
Dadurch, dass es einen integrierten Cache von 1024 Byte hat, greift es
nur alle 16000 Taktzyklen auf den Speicher zu.
Allerdings müssen diese Daten dann auch sehr schnell gelesen
werden, da sie in der Blank-Zeit des Monitors gelesen
werden.
Wir sind zu dem Ergebnis gekommen, dass eine Verteilung über
Prioritäten am Einfachsten ist. Auf Grund der
Abhängigkeiten bekommt die CPU die geringste Priorität, da
ihr Aussetzen das Terminieren der anderen Module
zur Folge hat und so irgendwann dann doch wieder zum Zuge kommt. Die
einzige vergeudete Zeit entsteht, wenn die
CPU gerade erst den nächsten Befehl lesen konnte und noch keine
neuen Dreiecksdaten an die 3D-Einheit weitergeben
konnte.
Ein Zeit-Multiplex hätte den Nachteil, dass man sehr viel Zeit mit
der Versorgung des VGA-Moduls vergeudet, auch wenn
das nicht nötig gewesen wäre. Insgesamt ist der Vorteil der
Priorisierung so einleuchtend, dass wir uns dafür entschieden
haben.
Der Bus besteht aus 32 Daten-,32 Adress-,3 Burst- sowie einer Request-,
einer Clock-, einer Busfree- und einer Acknowledgeleitung. Alle
Einheiten
sind über solch einen Bus mit dem DMA-Controller verbunden. Der
DMA fungiert
immer als Slave. Die vorgesehenen Burstleitungen sind derzeit nicht in
Benutzung
und sollten immer auf 0 stehen.
Wenn jetzt ein Master Daten aus dem RAM lesen will, muss er RW auf
low, Request auf high und an dem Adressbus die Adresse anlegen. Es kann
dann 1 bis n Zyklen dauern bis der DMA-Controller den Request
behandelt. Wenn die Daten aus dem Ram gelesen sind, setzt der
DMA-Controller Acknowledge auf high und im nächsten Takt
können die Daten dann gelesen werden. Im selbem Takt muss der
Master request auf low setzen, damit Daten nicht mehrfach gelesen
werden. BusFree bestätigt, dass der Aktuelle Request angenommen
wurde. Im Zyklus, nach dem BusFree high ging, kann ein neuer Request
gestartet werden.
Das Schreiben erfolgt analog, nur das RW auf high gesetzt wird und
dann auch die zu schreibenden Daten an DataOut anliegen müssen.
Der Controller entscheidet anhand einer Priorisierung der Master
über
den nächsten Request. Die Module mit der kleinsten Priorität
werden
immer zuerst behandelt.
| Priorität |
Modul |
Begründung |
| 1 |
VGA |
Ist auf einen konstanten Strom von Daten
angewiesen. |
| 2 |
Texture |
Nur texturierte Dreiecke kann man sehen. |
| 3 |
Pixel |
Wird dringend benötigt um Dreiecke
zeichnen zu können. |
| 4 |
CPU |
Kann man problemlos anhalten. |
Man könnte jetzt denken das die CPU zu wenig Zugriffe zugeteilt
bekommt. Aber wenn
die CPU keine neuen Daten bekommt, können auch die anderen Module
keine neuen
Daten bekommen und werden deshalb von selbst terminieren.
Die Schnittstelle eines Masters ist in VHDL folgendermaßen
deklariert:
adr_mastername : in std_logic_vector(31 downto 0);
datain_mastername : out std_logic_vector(31 downto 0);
dataout_mastername : in std_logic_vector(31 downto 0);
req_mastername : in std_logic;
ack_mastername : out std_logic;
bfree_mastername : out std_logic;
rw_mastername : in std_logic;
burst_mastername : in std_logic_vector(1 downto 0);
- datain_mastername Zu lesende Daten
- dataout_mastername Zu schreibende Daten
- adr_mastername Die Adresse für die Operation
- req_mastername high für neuen Request
- bfree_mastername high wenn Daten im nächsten Zyklus
bereitstehen bzw. geschrieben werden. Signal zum Zurücksetzen von
bus_req
- ack_mastername high wenn Daten zum lesen bereitstehen,
bzw. wenn sie geschrieben wurden.
- rw_mastername high zum Schreiben
- burst_mastername Derzeit immer 0
Am Anfang haben wir darüber nachgedacht, die UART über
"`Register"' an die CPU anzubinden und ein Programm die Daten von der
UART in den Speicher kopieren zu lassen. Wenn die CPU wider erwarten
nicht funktioniert, hat das jedoch den Nachteil, dass das Hauptprogramm
nicht hochgeladen werden kann und so das debuggen erschwert wird.
Deshalb haben wir uns entschieden, die UART direkt an den DMA
anzuschließen.
Anfangs hatten wir sehr große Probleme mit der fehlerfreien
Übertragung der Daten, deshalb haben wir uns entschlossen für
die Verifikation eine CRC32 anzuhängen. Die ankommenden
Datenpakete bestehen also derzeit aus 16 Datenbytes und 4 CRC bytes. Um
auch noch andere Befehle über die UART senden zu können, wird
außerdem bei dem ersten Byte unterschieden, ob es sich um Daten
oder einen Befehl handelt. Alle Bytes gehen in die CRC32 ein.
Das Protokoll ist denkbar einfach. Wenn das erste Byte den Wert 0xFF
hat, handelt es sich um einen Adressierungsbefehl. Die Nachfolgenden
vier Bytes werden dann als Addresse verstanden. Bei der Adresse werden
die untersten 2 bit weggelassen, weil sie nur unalignte Zugriffe
erzeugen würden.
Wenn jedoch das erste Byte 0xAA ist, werden die Daten in den
aufsteigenden Adressbereich geschrieben.
Nach jeder Übertragung wird kontrolliert, ob es einen Fehler
zwischen übertragener und berechneter CRC gab. Wenn es einen
Unterschied gab, wird ein Byte mit dem Wert 0x48 gesendet. Ansonsten
wird 0x45 gesendet wenn Daten gesendet wurden und 0x46 wenn ein
Adressierungsbefehl gesendet wurde.
Bei einer nicht richtigen CRC wird die Adresse wieder auf die Stelle
zurückgesetzt, die als Letztes gültig übertragen wurden.
Die CRC32 ist die Gleiche, die auch bei ZIP Archiven benutzt wird.
Für die Implementierung wurde der CRC Generator von
http://www.easics.com benutzt. Um jedoch das gleiche Ergebnis zu
erzielen, müssen die Daten "`verdreht"' werden. Man muß also
aus der Variable D:std_logic_vector(7 downto 0) ein std_logic_vector(0
to 7); machen. Die Ausgangssignale bleiben unverändert.
Weil es vorkam, dass unsere geschriebene Software sich nicht immer so
verhalten hat wie wir es von ihr erwartet haben, wurde ein Emulator
geschrieben, der die CPU nachbildet. Dieser allokiert 2 MB Speicher und
die Daten die normalerweise per UART eingespielt würden werden aus
einer Datei gelesen und anschließend alles so ausgeführt wie
es auch in unserem Projekt gemacht wurde. Um den Prozessor zu
simulieren, haben wir die in VHDL beschriebenen State Machines in
C++-Quellcode umgesetzt. Auf diese Weise konnten wir einige der
Software Fehler schon beheben, bevor die Hardware überhaupt
richtig lief.
Natürlich musste auch die dedizierte Hardware nachgebildet
werden. Dazu wird nach jedem simulierten Zugriff auf ein entsprechendes
Register, der sonst in Hardware in einen Fifo geschoben würde,
ausgeführt. Hier liegt dann auch eines der Probleme, die man im
Emulator nicht nachbilden kann. Nämlich die Bestimmung der
Zeitpunkte wann die Operationen der restlichen Einheiten fertig sind,
und wann welche Einheit einen Speicherzugriff bekommt.
Zur Visualisierung des Framebuffers wurde die GDI Library benutzt.
3D-Grafikprojekt
This document was generated using the
LaTeX2HTML
translator Version 2K.1beta (1.48)
Copyright © 1993, 1994, 1995, 1996,
Nikos Drakos,
Computer Based Learning Unit, University of Leeds.
Copyright © 1997, 1998, 1999,
Ross Moore,
Mathematics Department, Macquarie University, Sydney.
The command line arguments were:
latex2html 3dProjektKorr.tex -split 0 -ps_images
The translation was initiated by root on 2003-07-16